An AI-assisted Digital Scholarly Editing System for Buddhist Studies.
Authors: Nagasaki, Kiyonori / Shimoda, Masahiro
Date: Thursday, 7 September 2023, 4:15pm to 5:45pm
Location: Main Campus, L 1 <campus:stage>
Abstract
In recent years, IIIF-compatible images of several xylographic Daizokyos (DZK, Series of Buddhist scriptures) have become available, mainly from Japanese research institutions and temples. Each DZK consists of approximately 5,000 to 6,000 scrolls converted into 150,000 to 190,000 digital images, and some used as a witness for the modern letterpress DZK and others not. In addition, printed materials that are fragments of them, as well as manuscripts that precede them, have been made available with IIIF by cultural institutions around the world. The situation has made authors build a Buddhist text database (Nagasaki, Tomabechi & Shimoda 2013) aggregating the IIIF images from various institutions. It enables researchers to have an opportunity to re-edit the existing critical edition, which is sometimes noted as needing re-editing due to errors or oversights. However, although the current system has made it possible to compare the page images of the witnesses with each other, the only way to check variants in the texts on the witnesses is to check each letter manually, which was time-consuming.
One way to solve this problem is to automatically contrast an OCRed text with the digital transcriptions of the existing edition if highly accurate OCR is available. However, until last year, although the development of OCR has long been undertaken, it has been challenging to find a suitable solution because many of the documents are manuscripts or woodblocks, which are not stable in character form, and because there are many different types of characters.
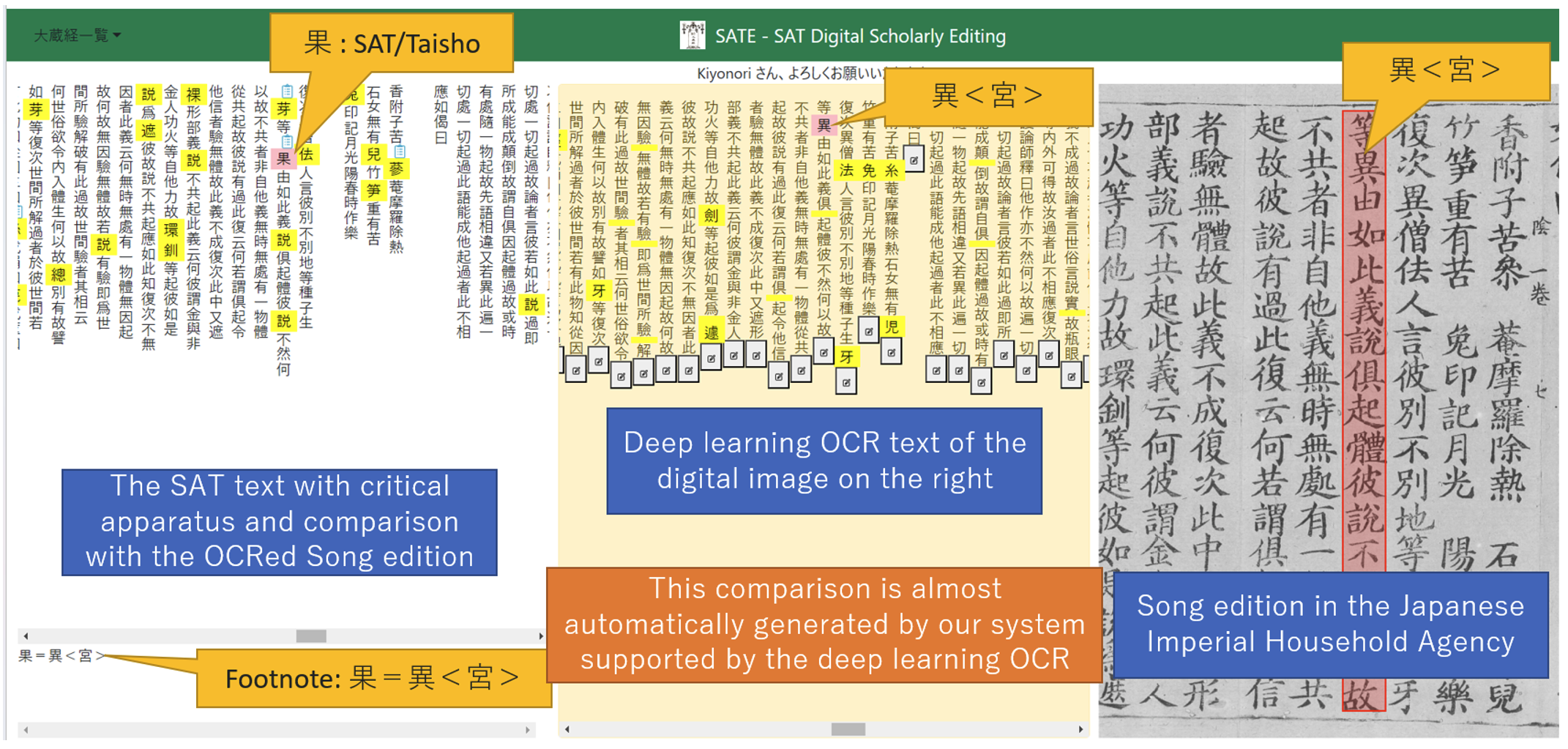
Under these circumstances, last year, the Next Generation Lab at the National Diet Library in Japan released an open-source OCR software (NDL OCR 2023) with deep learning technology for East Asian classics, which is more accurate than the previous ones, enabling automatic comparison between each OCRed diplomatic text (Text-D) and our text data digitized from a critical edition (Text-CE). The system detects variants between Text-D and Text-CE using the difflib module in Python.
Users of the system see the place of variants as yellow-marked texts on the windows of Text-CE (left window) and Text-D (center window). Users can see the variants on text data and an area shaded in red on the OCRed digital facsimile in IIIF, including the place of the variant characters. In Fig.1, a variant noted in the footnote of the critical edition has been confirmed via the OCRed text with the corresponding IIIF image. The system also allows users to find errors or oversights similarly. That is, if a yellow-marked character is different between both texts, a variant is not noted in the footnote, and the accuracy of the character in the OCRed text is confirmed with the IIIF image, it should be an oversight in the existing edition. Occasionally, textual errors may occur due to misidentification by the OCR software. Even in such cases, automatic contrast with Text-CE can significantly increase the likelihood of detecting errors.
Moreover, determining whether or not a mistake has been made is also easy to perform, as the IIIF image of the corresponding part can be easily focused with a single click. After checking the texts, authorized users can revise such errors in both texts in the system. As our project adopts TEI guidelines with double-endpoint-attached method, the system can include various witnesses without overlapping.
This means that the scholarly editing system using OCR text has finally become a realistic possibility in East Asian Buddhist studies.
Bibliography
Nagasaki, K., Tomabechi, T., & Shimoda, M. (2013). Towards a Digital Research Environment for Buddhist studies. Literary and Linguistic Computing, 28(2), 296–300. https://doi.org/10.1093/llc/fqs076
NDL OCR application for classics (NDL古典籍OCRアプリケーション), https://github.com/ndl-lab/ndlkotenocr_cli, accessed 2023-04-30.
About the authors
Kiyonori Nagasaki, Ph.D., is a senior fellow at the International Institute for Digital Humanities in Tokyo. His main research interest is developing digital frameworks for collaboration in Buddhist studies. He is also investigating the significance of digital methodology in the Humanities and promoting DH activities in Japan.
Masahiro Shimoda, Ph.D., is a former professor at the University of Tokyo, and a professor at Musashino University. He studies the formation process of Mahayana Buddhist scriptures and is also leading a project to build and develop the database of Buddhist Chinese texts (SAT).
Contribution Type
Keywords