Toward a TEI/RDF Encoding for Semantic Annotations: Concept and Implementation as LOD Editor
Authors: Ogawa, Jun / Nagasaki, Kiyonori / Nakamura, Satoru / Ohmukai, Ikki / Kitamoto, Asanobu
Date: Wednesday, 6 September 2023, 4:15pm to 5:45pm
Location: Main Campus, L 1.202 <campus:note>
Abstract
Over the years, the interoperability between TEI and external data models has been a prominent subject of discussion. Recently, the LINCS team explored the conversion from TEI to CIDOC-CRM1, while John Bradley introduced the TEI-based description of the Factoid Prosopography, earlier presented as RDB or RDF data2. In the same line, D. L. Schwartz delved into the description of Factoids in TEI3. In addition, ongoing theoretical discussions regarding the application of RDFa to the TEI schema can be found on the TEI GitHub issues4. All these studies contemplate how graph-structured data can be effectively conveyed in TEI/XML, advocating the use of TEI namespace in the LOD context. One of the main reasons behind adopting TEI/XML for LOD creation lies in its ability to represent detailed textual information more effectively than pure RDF representation2.
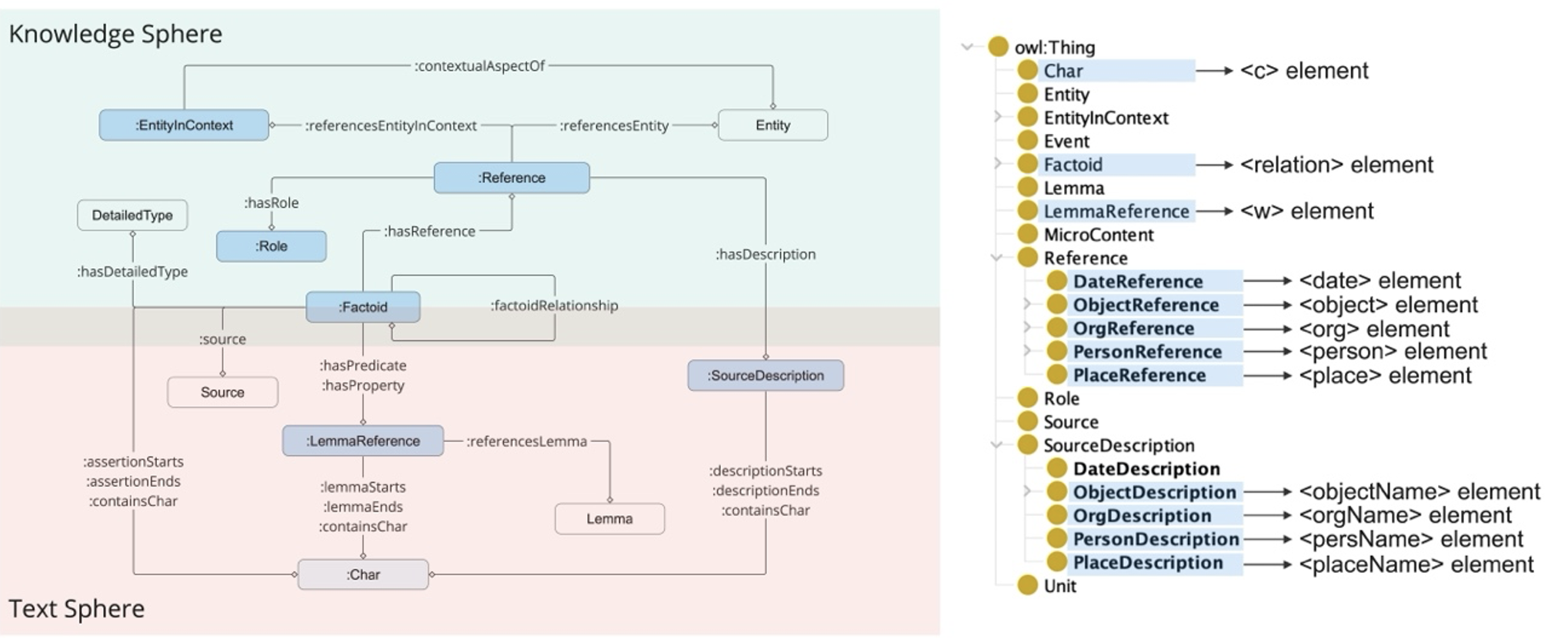
Ø. Eide’s research extensively explores both theoretical and practical aspects of TEI and data models5. Eide perceives TEI not only as a markup method but also as a model capable of compatibility and interoperability with diverse data structures. Building upon this discussion, we propose the concept of TEI/RDF encoding. In this approach, while the basic textual structure is marked with TEI/XML, encompassing characters and editorial marks, semantics beyond the character level, such as words, entities, events, and relationships, are described in RDF using a data model compatible with the TEI namespace. These RDF elements are then linked to the TEI/XML in quasi-standoff markup through references to @xml:id assigned to each <c> element. This linking allows for a flexible representation of the knowledge network in RDF while preserving the more effectively encoded textual features, like editorial marks, within TEI/XML (Fig. 1).

Using historical documents as a case study, we developed an ontology named HIMIKO (Historical Micro Knowledge and Ontology). The basic concept of this ontology is to capture the small pieces of historical information (Micro Knowledge in our terms), which would be about historical events, situations, or relationships, as a LOD resource encompassing the specific textual contexts and descriptions. In this sense, while rooted in the basic concept of Factoid Prosopography, this ontology expands significantly to enhance its referentiality to primary source descriptions6. Although HIMIKO is intended for RDF description, and therefore not XML-based, numerous classes and properties can be aligned with TEI schema concepts, as depicted in Fig. 2. Consequently, even though most elements, except <c>, aren’t directly encoded in XML format, it remains largely compatible with TEI/XML encoding.
The rationale behind restricting XML usage solely to textual descriptions is based on the belief that handling complex and multi-layered information is more feasible and appropriate in RDF. An illustration of this is shown in Fig. 3. Here, the issue of overlap makes it challenging to integrate multi-layered encoding of editorial markup and entity descriptions, unless a distinct representation for entities is employed.

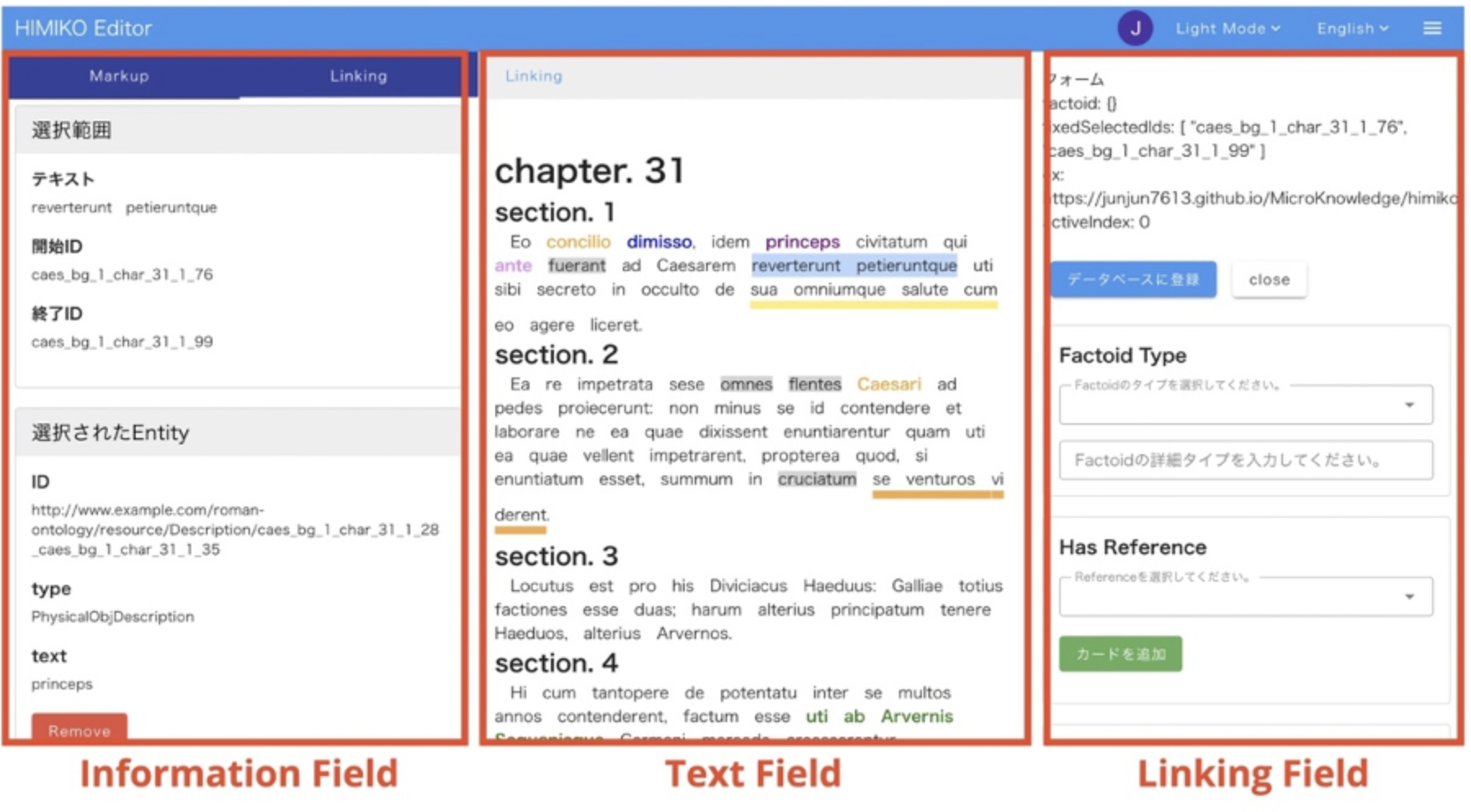
Thus, our approach considers TEI as a data model rather than a specific markup method, enabling an efficient encoding of text-related knowledge via RDF. This approach also contributes to reduced encoding costs by enabling separate processing of semantic information, potentially in a different format. It is for this purpose that we developed an editor6. Within this editor, the ‘Linking Field’ allows the creation of RDF data, which is basically independent of the XML syntax, based on minimally encoded TEI/XML data displayed in the ‘Text Field’ as an interactive text interface. Thus, users would not be required to manually edit either XML text markup or any RDF format, such as RDF/XML or Turtle. Our system shares similarities with CATMA7 in its standoff implementation, and with Recogito or LEAF-Writer8 in its data-linking system, while significantly supplementing them for more complex RDF knowledge representation.
Our study aligns with previous studies that view TEI as a data model and explore its integration with Linked Data format. Building upon these works, we establish a more detailed connection between TEI encoding and knowledge description, leading to a comprehensive implementation of Linked Data, or more specifically RDF, for representing text-related knowledge. Consequently, our study serves as a practical example of successful TEI/RDF implementation, showcasing the potential for more complex and context-depended representation of textual information within the broader context of knowledge networks.
Notes
-
C. Crompton, H. Zafar and A. Defours (2022), ‘Long Paper: LINCS’ Linked Workflow: Creating CIDOC-CRM from TEI,’ TEI2022 Conference Book, pp. 114-115. ↩
-
J. Bradley and D. Jakacki (2021), ‘Combining the Factoid Model with TEI: examples and conceptual challenges,’ poster at TEI Member’s Meeting 2021, https://hcommons.org/deposits/item/hc:42095. ↩ ↩2
-
D. L. Schwartz, N. P. Nathan and K. Torabi (2022), ‘Modeling a Born-Digital Factoid Prosopography using the TEI and Linked Data,’ Journal of the Text Encoding Initiative [Online], Rolling Issue, https://journals.openedition.org/jtei/3979. ↩
-
Ø. Eide (2015), ‘Ontologies, Data Modeling, and TEI,’ Journal of Text Encoding Initiative [Online], Issue 8, https://journals.openedition.org/jtei/1191. ↩
-
J. Ogawa, I. Ohmukai, S. Nakamura and A. Kitamoto (2023) ‘Collecting Pieces of Historical Knowledge from Documents: Introduction of HIMIKO (Historical Micro Knowledge and Ontology),’ short paper, DH 2023, Graz/Austria, July 10-14 2023, https://www.conftool.pro/dh2023/index.php?page=browseSessions&form_session=93#paperID810. ↩ ↩2
-
S. Brown, D. Jakacki, J. Cummings, M. Ilovan, L. Frizzera, R. Milio and C. Black (2022), ‘Workshop 6: Engaging TEI Editors Through LEAF-Writer,’ TEI 2022 Conference Book, pp. 28-30. ↩
Contribution Type
Keywords