3D Text Encoding and TEI: Text, Editions, and Spatiality
Authors: Ogawa, Jun / Nagasaki, Kiyonori / Kitamoto, Asanobu
Date: Thursday, 7 September 2023, 4:15pm to 5:45pm
Location: Main Campus, L 1 <campus:stage>
Abstract
The incorporation of 3D technologies within the realm of digital humanities has emerged as a captivating subject for numerous scholars. A significant challenge lies in determining the most effective representation of interconnected information, encompassing meta- and para-data of 3D models, images, movies, and textual content, within this innovative multi-dimensional environment1.
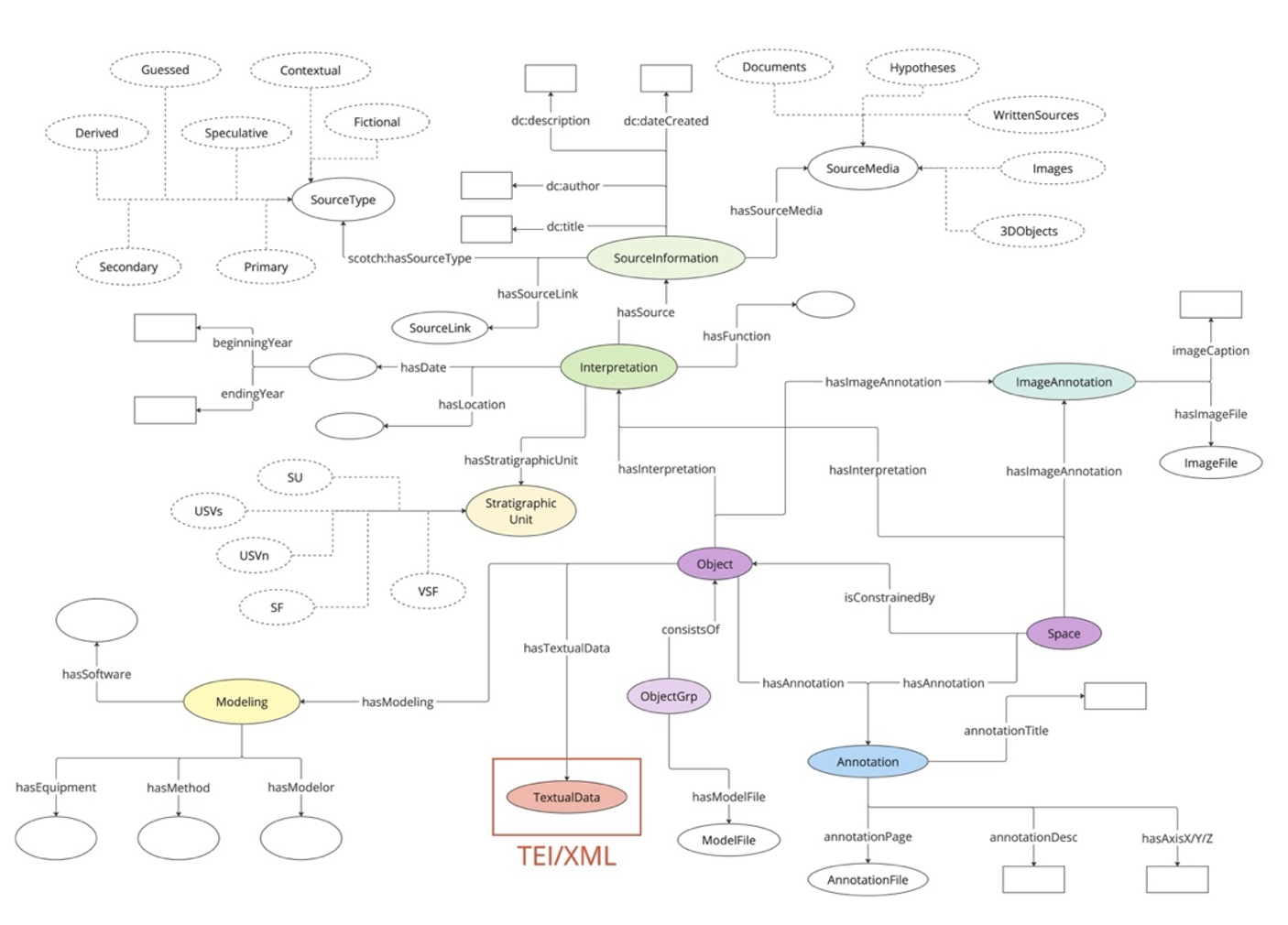
To address this, we designed a conceptual model for a 3D knowledge network (Fig. 1), ensuring more accurate utilization of 3D information in terms of academic credibility, multiple interpretations, and data usability. While preceding studies like ADS Data Model2, SCOTCH3, or HBIM4 have touched on similar discussions for 3D information description, the specific challenge of 3D text representation and the interplay between textuality and spatiality remain insufficiently explored even in those works. How can we effectively encode text inscribed on 3D objects or positioned within 3D space, preserving its spatial context while maintaining a well-structured text edition? This crucial aspect warrants further investigation to enhance the integration of textual content within the 3D landscape.
In this poster, we present an enhanced method for representing text in a 3D context, building upon our previous discussions at TEI 2022 where we suggested the use of the <sourceDoc>5. Our newly developed approach allows for a more refined mapping of text data and 3D spatial information, down to the character level, by leveraging the <c>. Additionally, we have extended this method to automatically render detailed textual features encoded in existing TEI tag sets, such as <corr>, <expan>, or <del>, into the 3D space. Through these advancements, we achieve a more practical and elaborate representation, bridging the gap between textual content and the 3D environment effectively.

Fig. 2 represents a fragment of sample EpiDoc markup, focusing on a single word within a specific inscription: “L(ucio).” The word “L(ucio)” is unequivocally identified as an ablative form of a Latin personal name, and it is accompanied by an abbreviation. This abbreviation is systematically encoded using the <expan>, following the specification of the EpiDoc schema. Interestingly, a discrepancy emerges between our model and the EpiDoc schema concerning the placement of the aforementioned text. While the EpiDoc schema traditionally locates such text within the <text> block, our model takes a different approach. In our proposed framework, the text is encoded within the <surface>, incorporating an attribute of @type=“text”, which serves as a grandchild element of the <sourceDoc>.
To identify the letter ‘L’ within the text, we utilize a <c> tag, augmented with an @facs value corresponding to the <zone> in another <surface> block with @type=“position”. This strategic linkage enables the explicit representation of spatial information, encompassing X-Y-Z coordinate and rotation. As a consequence, the encoded text can be seamlessly rendered into the 3D space. As our model also permits the connection of lines to the <zone> information, entire lines within the inscription can be displayed in the 3D realm.
In our research, we not only propose novel encoding methods for representing 3D textuality but also take a step further by transforming TEI-encoded data into a Linked Open Data (LOD) resource. By doing so, we establish valuable connections within a vast network of 3D knowledge, transcending the boundaries of individual texts or objects. The concept of this interconnected network is visually depicted in Fig. 1. Specifically, we model TEI/XML data as an instance of the :TextualData class, showcasing its importance in preserving textual information. This textual data is then linked to an :Object instance through the :hasTextualData property, establishing a meaningful relationship between the represented object and its associated textual content.
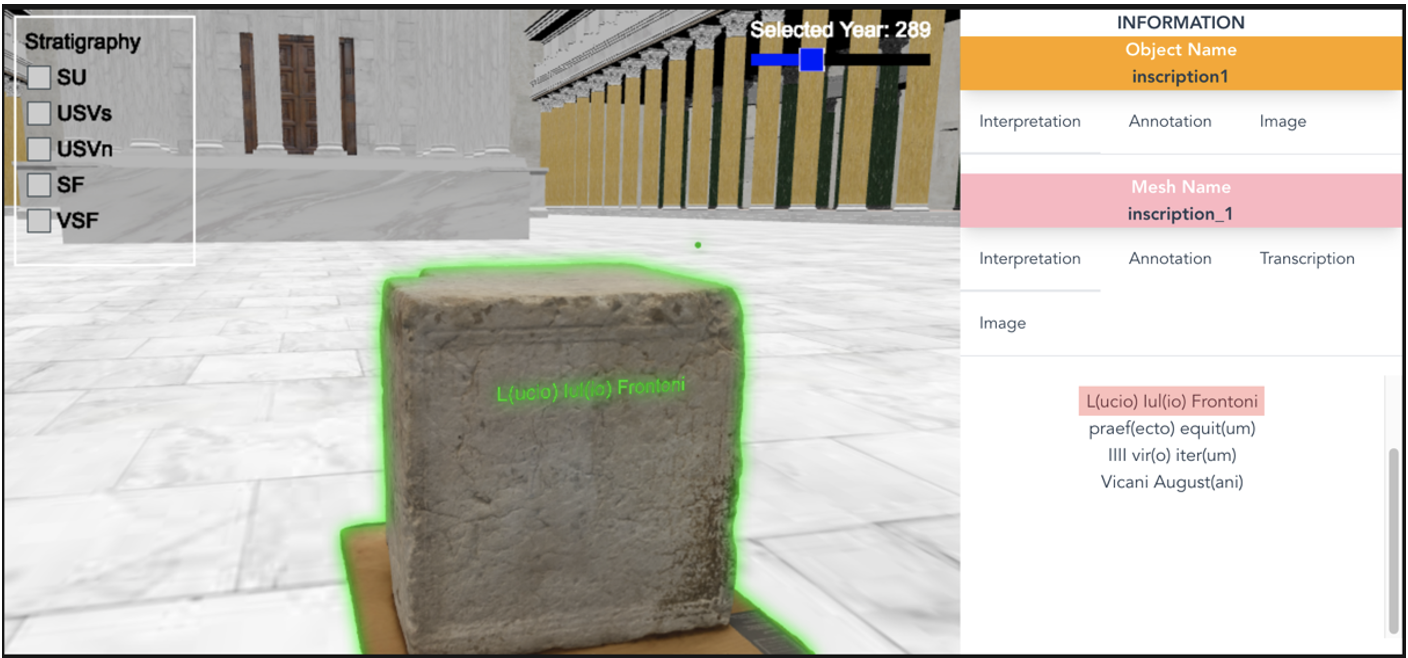
Besides suggesting the new encoding methods for 3D textuality, we decided to make a TEI-encoded data function as a LOD resource, linking it to the wider network of 3D knowledge not limited to any single text or object. Such a network has already been shown in Fig. 1, where TEI/XML data is represented as an instance of :TextualData class connected to an :Object instance by :hasTextualData property. We have developed a 3D visualization system (Fig. 3) that enables the visualization of such a knowledge cloud, capturing the intricate connections and relationships within a vast repository of knowledge.
Through this approach, we bridge the gap between textual information and 3D representations, enabling seamless integration and accessibility of data within the broader 3D knowledge landscape. This interconnectedness not only enhances the understanding of individual texts and objects but also fosters a more comprehensive and interconnected understanding of 3D textuality as a whole.
Notes
-
Susan Schreibman & Costas Papadopoulos (2019), ‘Textuality in 3D: three-dimensional (re)constructions as digital scholarly editions,’ International Journal of Digital Humanities, vol. 1, pp. 221-233. ↩
-
Martina Trognitz, Kieron Niven and Valentijn Gilissen (2016), “3D Models in Archaeology: A Guide to Good Practice.” In Guides to Good Practice, by Archaeology Data Service / Digital Antiquity. University of York, UK: Archaeological Data Service. ↩
-
Valeria Vitale (2017), ‘Rethinking 3D digital visualization: from photorealistic visual aid to multivocal environment to study and communicate cultural heritage,’ PhD Thesis, King’s College London. ↩
-
Martina Attenni (2019), ‘Informative Models for Architectural Heritage,’ Heritage 2019, pp. 2067-2089. ↩
-
Jun Ogawa et al. (2022), ‘Poster: Text as Object: Encoding the data for 3D annotation in TEI,’ TEI 2022 Conference Book, pp. 86-88. ↩
-
Bernard Rémy et al (2004), Inscriptions Latines de Narbonnaise (I.L.N.), V. 2. Vienne, CNRS Editions, p. 268. ↩
Contribution Type
Keywords