TEI semantic in graph-based digital scholarly editions
Authors: Kuczera, Andreas
Date: Thursday, 7 September 2023, 2:15pm to 3:45pm
Location: Main Campus, L 1.202 <campus:note>
Abstract
Digital editions are now established as state of the art in the humanities and cultural studies. A large number of source types from different eras are now digitally edited. Thanks to their almost unlimited editorial possibilities, digital edition processes have proven superior to pure print publication (for the current discussion, see Driscoll/Pierazzo 2016). The shift from print to digital edition brings with it a wealth of search and evaluation possibilities and also enables the development and differentiation of semantic markup (summarised by Sahle 2013). The Text Encoding Initiative (TEI) has established itself as an authoritative standard in this field. Correspondence data in particular are the focus of numerous internationally networked research projects. One example of digital letter editions is the European cooperation project Reassembling the Republic of Letters led by Howard Hotson and Thomas Wallnig, which has developed overarching standards in the modelling and digital analysis of correspondence data (cf. Hotson/Wallnig 2019, http://republicofletters.stanford.edu/). At the national level, digital editions of early modern correspondence such as the projects PROPYLÄEN. Goethes Biographica (https://goethe-biographica.de/), Jean Paul – Sämtliche Briefe digital (https://www.jeanpaul-edition.de/start.html), edition humboldt digital (https://edition-humboldt.de/) and the Carl-Maria-von-Weber-Gesamtausgabe (https://weber-gesamtausgabe.de/de/Index) are examples of active Digital Humanities research in this field. The web service correspSearch of the Berlin-Brandenburg Academy of Sciences and Humanities (BBAW) should also be mentioned in particular, which offers the networking of numerous editions and thus enables research perspectives beyond the individual edition.
It should be noted, however, that these editions focus on visual access to the material and hardly provide for data-based access.
Graph-based digital editions offer both visual and data-centred access. They thus enable the analysis of semantic information in networked form and transfer it into knowledge graphs (Kuczera 2020). Thus, not only multiple representations adapted to the respective interface become possible from a structured text (such as HTML, PDF, ePub etc.), but also pattern-based queries on content aspects. In these functions, the graph-based digital edition emphasises the usage aspect over the reading function: ‘not merely reading, but using the edition’ (Gabler 2010). This usage aspect manifests itself, among other things, in the finely granular search and filter options of the web and data interfaces. The search functions of graph-based digital editions are semantically oriented and can show connections in the strongly networked research data and make lines of connection visible. This gives users more room for their own content analyses, e.g. via faceted searches, via data mining methods or semantic or pattern-based search options (Hörnschemeyer 2017). A graph structure that models data flexibly linkable as nodes and edges of a network is particularly suitable for this, as it can also map overlapping multidimensional annotation hierarchies (Kuczera 2020). This allows different annotation levels, e.g. layout, formatting, semantics, content indexing and annotation, to be modelled and evaluated together. Examples of the implementation of digital graph-based editions are the projects Die Sozinianischen Briefwechsel (https://sozinianer.mni.thm.de/home) and Das Buch der Briefe der Hildegard von Bingen. Genesis – Structure – Composition (https://liberepistolarum.mni.thm.de/home). Both rely on graph technologies through the combination of graph database (neo4j) and graph-based edition environment in conjunction with TEI semantics, both in data modelling and in editorial practice (Kuczera 2020).
The current state of digital editions is the use of XML. Here is an example:

Text and annotations are captured together in XML structures. The text still remains readable in our simple example. However, it is obvious that with more annotations, which may also come from different people, the complexity increases very quickly. In addition, with XML the so-called containment applies, i.e. different annotations may not overlap. A new approach to store text and annotations is the modeling of text and annotations in a graph.
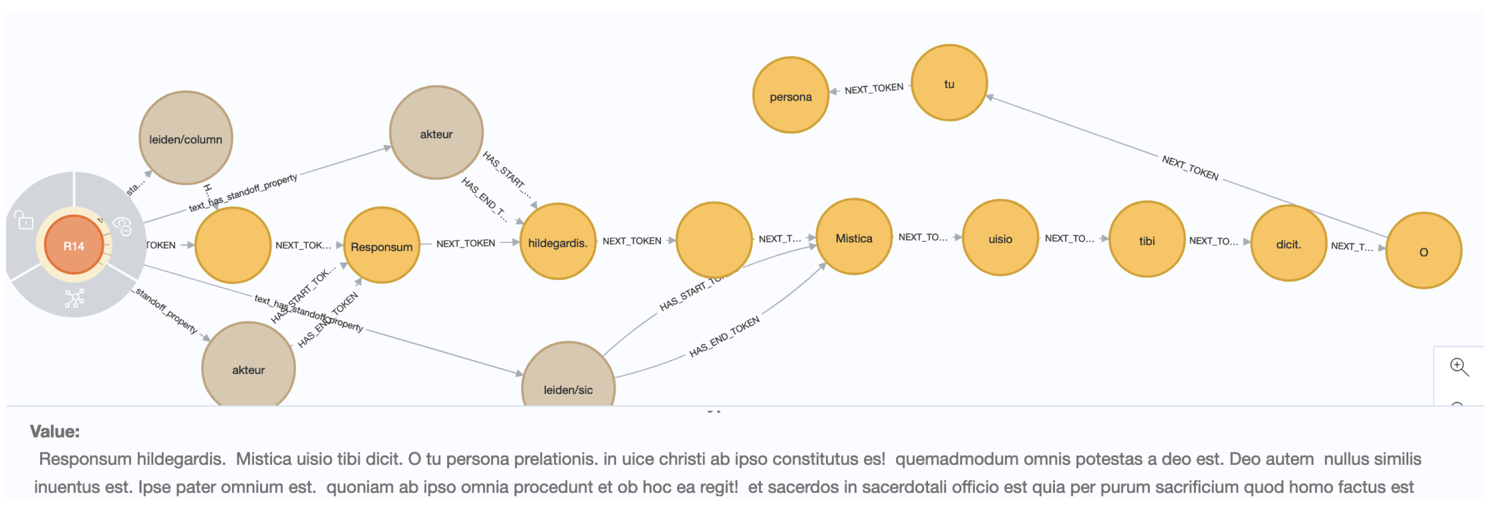
In this case, the words are put into (yellow) token nodes, context. Annotations are attached to this text chain in additional (brown) nodes.
Thomas Efer has also described such a model in his dissertation.
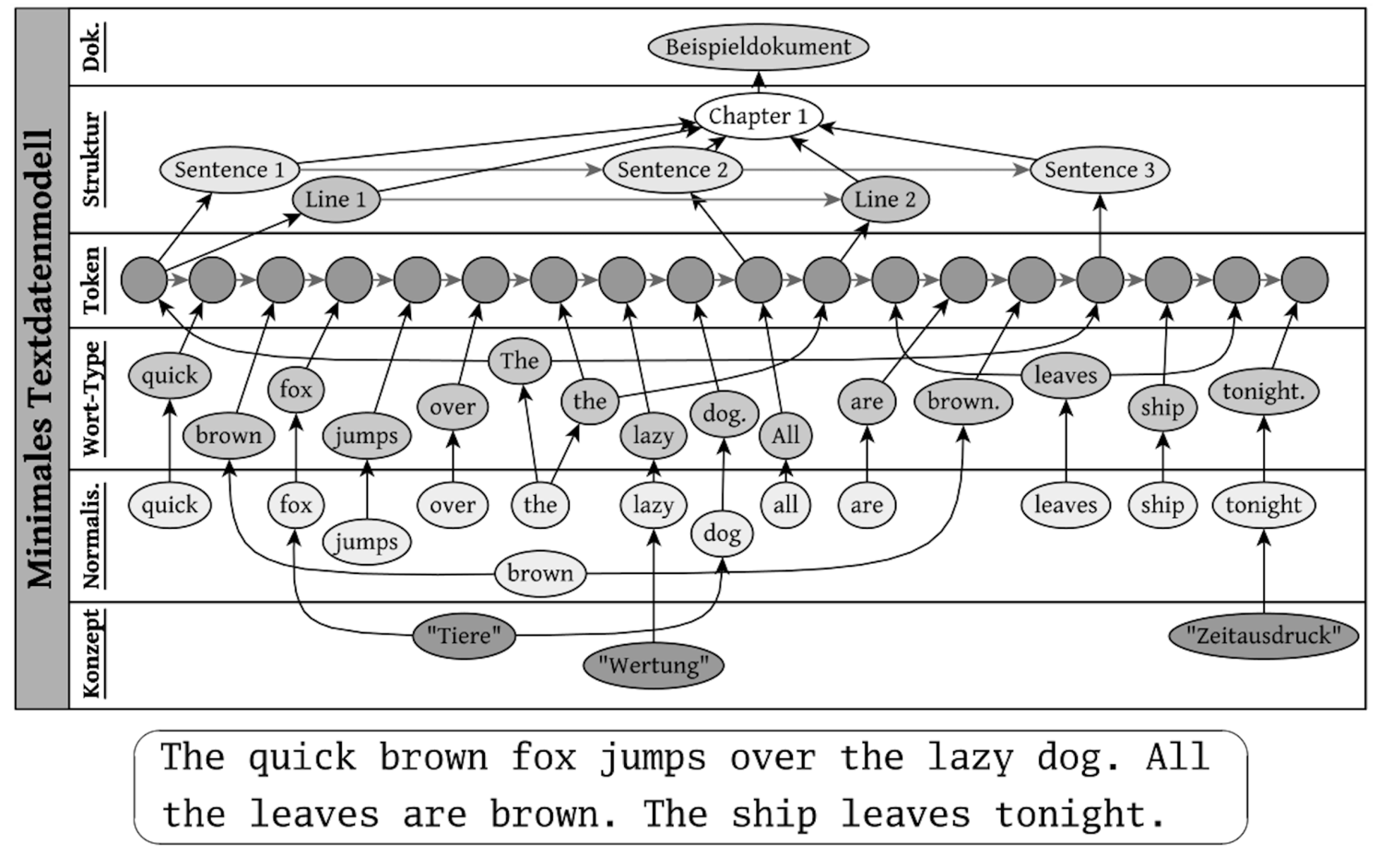
(Efer 2016) ends at the token level. In our use case, another layer is added with the individual characters in the nodes, as shown in the following figure.
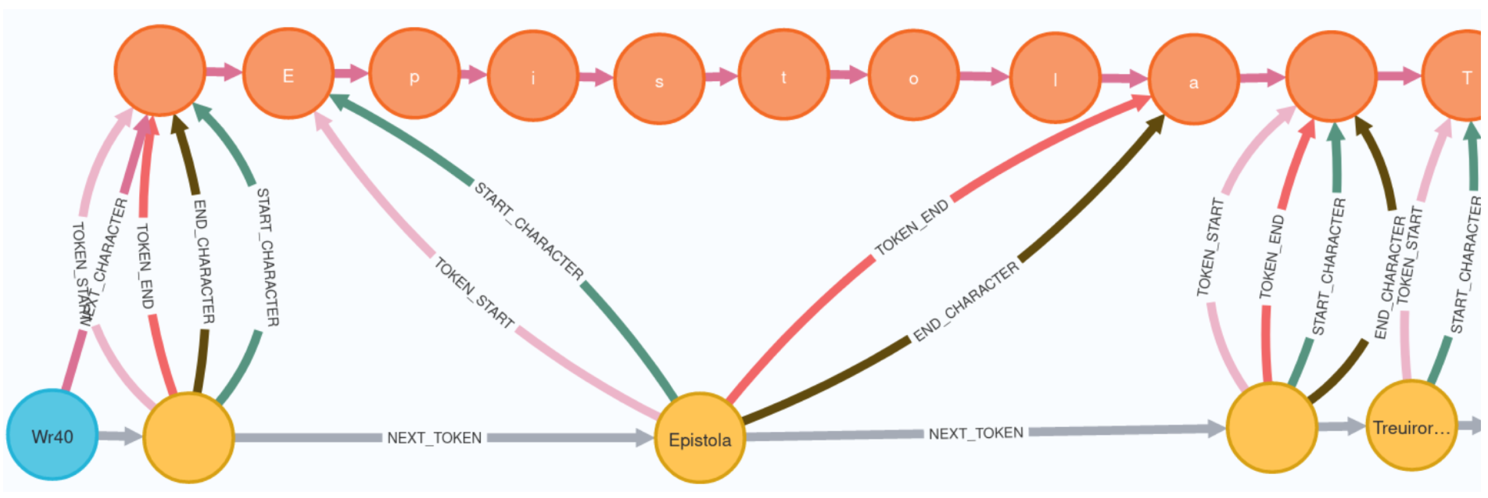
(see also: [https://liberepistolarum.mni.thm.de).
The Character-Chain models whitespace as explicit nodes, so the model can be agnostic about what is to be defined as a token.
The presentation will show the graph-based scholarly editions of SBW and Hildegard which aim to give full flexiblity within tha annotation process to the editor while keeping interoperatbility with using the semantic of the TEI.
Bibliography
Driscoll/Pierazzo 2016: Matthew James Driscoll/Elena Pierazzo (Hg.), Digital scholarly editing: Theories and practices, Cambridge 2016.
Gabler 2010: Hans Walter Gabler, ‘Theorizing the Digital Scholarly Edition’. In: Literature Compass 7/2 (2010), S. 43–56. https://doi.org/10.1111/j.1741-4113.2009.00675.x.
Hörnschemeyer 2017: Jörg Hörnschemeyer, Textgenetische Prozesse in Digitalen Editionen, Diss. Köln 2017.
Hotson/Wallnig 2019: Howard Hotson, Thomas Wallnig (Hg.), Reassembling the Republic of Letters in the Digital Age. Standards, Systems, Scholarship, Göttingen 2019.
Kuczera 2020: Andreas Kuczera, ‘TEI Beyond XML – Digital Scholarly Editions as Provenance Knowledge Graphs’. In: Tara Andrews, Franziska Diehr, Thomas Efer, Andreas Kuczera, Joris van Zundert (Hg.), Graph Technologies in the Humanities – Proceeding 2020, published at http://ceur-ws.org/Vol-3110/paper6.pdf.
Sahle 2013: Patrick Sahle, Digitale Editionsformen. Zum Umgang mit der Überlieferung unter den Bedingungen des Medienwandels, Textbegriffe und Recodierung, 3 Bde., Norderstedt 2013 (Schriften des Instituts für Dokumentologie und Editorik, Bde. 7–9).
About the author
Andreas Kuczera is professor for applied digital methodology in the humanities and social sciences at the university of applied science Gießen. He works on graph technologies in the digital humanities and graph based digital scholarly editions.
Contribution Type
Keywords